Hadoop clusters with Kove® XPD™ persistent memory
Mark Kerzner (mark@hadoopilluminated.com), Greg Keller (greg@r-hpc.com), Ivan Lazarov (ivan.lazarov@shmsoft.com), Sujee Maniyam (sujee@hadoopilluminated.com)
Abstract
Since the Hadoop cluster stores its most vital information on its NameNode server in RAM, this represents a potential point of failure and source of data loss. The usual precautions take the form of storing this information on multiple local hard drives and on a remote one. However, even if the data is preserved in the case of failure, it make take many hours to restore the cluster to its operation.
In contrast, by running the Hadoop NameNode on the Kove XPD, one can achieve very fast restoration of Hadoop functionality after such failures as a power loss or motherboard failure. This is accomplished by running a modified version of the Hadoop software, which maps the memory space of the NameNode onto the Kove XPD and can be found on GitHub here https://github.com/markkerzner/nn_kove.
Standard RAM presents yet another limitation on Hadoop: it makes it limited in size. One can only store as much data (files and blocks) as the RAM will allow. By contrast, Kove XPD is unlimited in size, and thus using it results in the removal of this limitation on the Hadoop cluster size.
Background
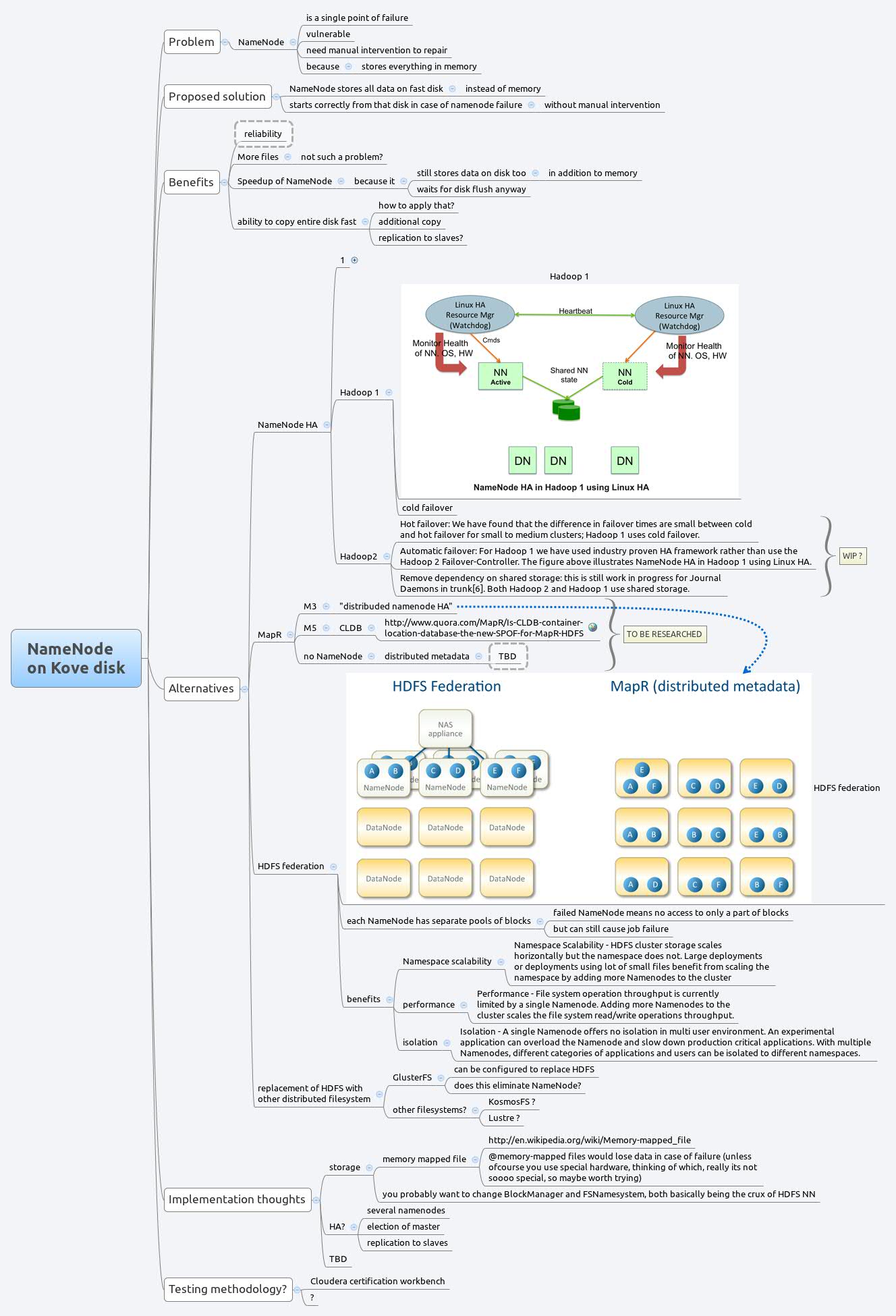
The Hadoop NameNode saves all of its block and file information in memory. This is done for the sake of efficiency, but it is naturally a single point of failure. There are multiple approaches to alleviate this SPOF, ranging from NameNode HA in Hadoop 2 to distributed NameNode.
However, a very enticing prospect is running NameNode on persistent memory, provided by the Kove XPD device.
The advantages of this implementation would be twofold.
1. Persistent memory is resistant to power failure. If this approach is proven viable, the software architecture for Hadoop NameNode on Kove can be simplified.
2. The size of the Kove memory is virtually unlimited, and these devices can be scaled well beyond a terabyte. With this much memory, the NameNode can store much more information, lifting the limitations on the number of files stored in Hadoop and obviating the need for federation.
The diagram below summarizes our thoughts up until this point.
Possible approaches
Here is the summary of our approaches we have tried.
Given that the NameNode stores following data in memory (simplified view), we have these major actors.
machine -> blockList (DataNodeMap, DatanodeDescriptor, BlockInfo)
block -> machineList (BlocksMap, BlockInfo)
Also these structures are referenced within FSImage structures (INode, FSDirectory) and some additional structures like CorruptReplicasMap, recentInvalidateSets, PendingBlockInfo, ExcessReplicateMap, PendingReplicationBlocks, UnderReplicatedBlocks.
All structures of interest are centered around FSNamesystem and are relatively tightly coupled, which implies careful refactoring with small steps.
1). Client -> Namenode
DFSClient
DFSOutputStream
namenode.addBlock (through RPC)
FSNameSystem.getAdditionalBlock()
lease
replicator.chooseTargets() -> DatanodeDesciptor[]
newBlock = allocateBlock(src, pathINodes);
FSDirectory.addBlock
// associate the new list of blocks with this file
namesystem.blocksMap.addINode(block, fileNode);
BlockInfo blockInfo = namesystem.blocksMap.getStoredBlock(block);
fileNode.addBlock(blockInfo);
pendingFile.setTargets(targets);
2). Client -> Datanode
connect to Datanode directly and transfer data...

Data exchange with Kove requires usage of special buffer registered with API. Registration takes time (about 100 microseconds), and same for copying data to/from buffers (each read/write about 1 microsecond).
Thus we have 4 ways to use it:
a. Create and register big buffer ourselves and do all modifications right inside the buffer. The buffer has to fit into normal memory. This is the fastest: buffer is created once at the start of NameNode, and cost of data transfer to/from other memory areas is minimized. This is the question: “Will it be easy to implement access to ‘native’ data structure from DataNode and does this bring more overhead?” This is likely the longest to implement.
b. Create and register smaller buffer(s) ourselves and use them multiple times for different chunks of data. This will require moving data to and from buffers which takes some time. But hopefully this also means fewer changes in DataNode data structures. Not limited to normal memory size.
c. Some combination of (a) and (b): try to cache most frequently/recently accessed areas (blocks?) in buffers registered for data exchange. When a certain area is in memory, we modify it in place and transfer to Kove. If not, we obsolete some buffer and use it for area of interest. May be an improvement over (b) but additional code to deal with caching, and need to see what overhead will caching itself give.
d. Have API registering memory and transferring the data behind the scenes. Easiest to implement, but probably the slowest: will read/write to library created buffers and occasionally have new buffers registered
Our implementation
In the end, we have implemented the NameNode changes using the EHCache library. Ehcache is an open source, standards-based cache for boosting performance, offloading your database, and simplifying scalability. It's the most widely-used Java-based cache because it's robust, proven, and full-featured.
We used it to replace the Java objects with EHCache objects and stored them to the XPD. Now came the time to test.
This implementation can be found on github here, https://github.com/markkerzner/nn_kove.
Testing
For testing with used NNBench and a combination of teragen/terasort. The results of the runs are given below.
One may notice that the performance of the cluster when using Kove is about 50% of the in-memory Hadoop code. This is to be expected. For our initial prototype treated the Kove XPD as KDSA block device, since it was easier to implement. The proper way, however, will be to use direct writes with Java to C interface, which has the performance of twice the block device. Thus, with the more meticulous implementation we would achieve the speed comparable to in-memory Hadoop code.
Appendix: test results
There are four groups of test results given below.
============ BLOCKSMAP + KOVE ============
---- terasort ----
hadoop jar hadoop-examples-1.1.2.jar teragen 500000 /user/hduser/terasort-input
hadoop jar hadoop-examples-1.1.2.jar terasort /user/hduser/terasort-input /user/hduser/terasort-output
13/08/07 07:12:53 INFO mapred.JobClient: map 0% reduce 0%
13/08/07 07:12:58 INFO mapred.JobClient: map 100% reduce 0%
13/08/07 07:13:05 INFO mapred.JobClient: map 100% reduce 33%
13/08/07 07:13:07 INFO mapred.JobClient: map 100% reduce 100%
13/08/07 07:13:07 INFO mapred.JobClient: Job complete: job_201308070712_0002
13/08/07 07:13:07 INFO mapred.JobClient: Counters: 30
13/08/07 07:13:07 INFO mapred.JobClient: Job Counters
13/08/07 07:13:07 INFO mapred.JobClient: Launched reduce tasks=1
13/08/07 07:13:07 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=6462
13/08/07 07:13:07 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
13/08/07 07:13:07 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
13/08/07 07:13:07 INFO mapred.JobClient: Rack-local map tasks=2
13/08/07 07:13:07 INFO mapred.JobClient: Launched map tasks=2
13/08/07 07:13:07 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=9238
13/08/07 07:13:07 INFO mapred.JobClient: File Input Format Counters
13/08/07 07:13:07 INFO mapred.JobClient: Bytes Read=50000000
13/08/07 07:13:07 INFO mapred.JobClient: File Output Format Counters
13/08/07 07:13:07 INFO mapred.JobClient: Bytes Written=50000000
13/08/07 07:13:07 INFO mapred.JobClient: FileSystemCounters
13/08/07 07:13:07 INFO mapred.JobClient: FILE_BYTES_READ=51000264
13/08/07 07:13:07 INFO mapred.JobClient: HDFS_BYTES_READ=50000218
13/08/07 07:13:07 INFO mapred.JobClient: FILE_BYTES_WRITTEN=102164352
13/08/07 07:13:07 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=50000000
13/08/07 07:13:07 INFO mapred.JobClient: Map-Reduce Framework
13/08/07 07:13:07 INFO mapred.JobClient: Map output materialized bytes=51000012
13/08/07 07:13:07 INFO mapred.JobClient: Map input records=500000
13/08/07 07:13:07 INFO mapred.JobClient: Reduce shuffle bytes=51000012
13/08/07 07:13:07 INFO mapred.JobClient: Spilled Records=1000000
13/08/07 07:13:07 INFO mapred.JobClient: Map output bytes=50000000
13/08/07 07:13:07 INFO mapred.JobClient: Total committed heap usage (bytes)=602996736
13/08/07 07:13:07 INFO mapred.JobClient: CPU time spent (ms)=6860
13/08/07 07:13:07 INFO mapred.JobClient: Map input bytes=50000000
13/08/07 07:13:07 INFO mapred.JobClient: SPLIT_RAW_BYTES=218
13/08/07 07:13:07 INFO mapred.JobClient: Combine input records=0
13/08/07 07:13:07 INFO mapred.JobClient: Reduce input records=500000
13/08/07 07:13:07 INFO mapred.JobClient: Reduce input groups=500000
13/08/07 07:13:07 INFO mapred.JobClient: Combine output records=0
13/08/07 07:13:07 INFO mapred.JobClient: Physical memory (bytes) snapshot=615641088
13/08/07 07:13:07 INFO mapred.JobClient: Reduce output records=500000
13/08/07 07:13:07 INFO mapred.JobClient: Virtual memory (bytes) snapshot=2303033344
13/08/07 07:13:07 INFO mapred.JobClient: Map output records=500000
13/08/07 07:13:07 INFO terasort.TeraSort: done
map() completion: 1.0
reduce() completion: 1.0
Counters: 30
Job Counters
Launched reduce tasks=1
SLOTS_MILLIS_MAPS=6462
Total time spent by all reduces waiting after reserving slots (ms)=0
Total time spent by all maps waiting after reserving slots (ms)=0
Rack-local map tasks=2
Launched map tasks=2
SLOTS_MILLIS_REDUCES=9238
File Input Format Counters
Bytes Read=50000000
File Output Format Counters
Bytes Written=50000000
FileSystemCounters
FILE_BYTES_READ=51000264
HDFS_BYTES_READ=50000218
FILE_BYTES_WRITTEN=102164352
HDFS_BYTES_WRITTEN=50000000
Map-Reduce Framework
Map output materialized bytes=51000012
Map input records=500000
Reduce shuffle bytes=51000012
Spilled Records=1000000
Map output bytes=50000000
Total committed heap usage (bytes)=602996736
CPU time spent (ms)=6860
Map input bytes=50000000
SPLIT_RAW_BYTES=218
Combine input records=0
Reduce input records=500000
Reduce input groups=500000
Combine output records=0
Physical memory (bytes) snapshot=615641088
Reduce output records=500000
Virtual memory (bytes) snapshot=2303033344
Map output records=500000
---- nn bench ----
hadoop jar hadoop-test-1.1.2.jar nnbench -operation create_write -maps 2 -reduces 1 -blockSize 1 -bytesToWrite 20 -bytesPerChecksum 1 -numberOfFiles 100 -replicationFactorPerFile 1
13/08/07 07:53:08 INFO hdfs.NNBench: -------------- NNBench -------------- :
13/08/07 07:53:08 INFO hdfs.NNBench: Version: NameNode Benchmark 0.4
13/08/07 07:53:08 INFO hdfs.NNBench: Date & time: 2013-08-07 07:53:08,57
13/08/07 07:53:08 INFO hdfs.NNBench:
13/08/07 07:53:08 INFO hdfs.NNBench: Test Operation: create_write
13/08/07 07:53:08 INFO hdfs.NNBench: Start time: 2013-08-07 07:45:15,177
13/08/07 07:53:08 INFO hdfs.NNBench: Maps to run: 2
13/08/07 07:53:08 INFO hdfs.NNBench: Reduces to run: 1
13/08/07 07:53:08 INFO hdfs.NNBench: Block Size (bytes): 1
13/08/07 07:53:08 INFO hdfs.NNBench: Bytes to write: 20
13/08/07 07:53:08 INFO hdfs.NNBench: Bytes per checksum: 1
13/08/07 07:53:08 INFO hdfs.NNBench: Number of files: 100
13/08/07 07:53:08 INFO hdfs.NNBench: Replication factor: 1
13/08/07 07:53:08 INFO hdfs.NNBench: Successful file operations: 200
13/08/07 07:53:08 INFO hdfs.NNBench:
13/08/07 07:53:08 INFO hdfs.NNBench: # maps that missed the barrier: 0
13/08/07 07:53:08 INFO hdfs.NNBench: # exceptions: 0
13/08/07 07:53:08 INFO hdfs.NNBench:
13/08/07 07:53:08 INFO hdfs.NNBench: TPS: Create/Write/Close: 65
13/08/07 07:53:08 INFO hdfs.NNBench: Avg exec time (ms): Create/Write/Close: 60.03
13/08/07 07:53:08 INFO hdfs.NNBench: Avg Lat (ms): Create/Write: 3.58
13/08/07 07:53:08 INFO hdfs.NNBench: Avg Lat (ms): Close: 56.375
13/08/07 07:53:08 INFO hdfs.NNBench:
13/08/07 07:53:08 INFO hdfs.NNBench: RAW DATA: AL Total #1: 716
13/08/07 07:53:08 INFO hdfs.NNBench: RAW DATA: AL Total #2: 11275
13/08/07 07:53:08 INFO hdfs.NNBench: RAW DATA: TPS Total (ms): 12006
13/08/07 07:53:08 INFO hdfs.NNBench: RAW DATA: Longest Map Time (ms): 6143.0
13/08/07 07:53:08 INFO hdfs.NNBench: RAW DATA: Late maps: 0
13/08/07 07:53:08 INFO hdfs.NNBench: RAW DATA: # of exceptions: 0
-------------------------------------------------------------------------------------------------------------------
============ BLOCKSMAP + DISK ============
---- terasort ----
hadoop jar hadoop-examples-1.1.2.jar teragen 500000 /user/hduser/terasort-input
hadoop jar hadoop-examples-1.1.2.jar terasort /user/hduser/terasort-input /user/hduser/terasort-output
13/08/07 08:06:46 INFO mapred.JobClient: Running job: job_201308070806_0002
13/08/07 08:06:47 INFO mapred.JobClient: map 0% reduce 0%
13/08/07 08:06:52 INFO mapred.JobClient: map 100% reduce 0%
13/08/07 08:06:59 INFO mapred.JobClient: map 100% reduce 33%
13/08/07 08:07:01 INFO mapred.JobClient: map 100% reduce 100%
13/08/07 08:07:01 INFO mapred.JobClient: Job complete: job_201308070806_0002
13/08/07 08:07:01 INFO mapred.JobClient: Counters: 30
13/08/07 08:07:01 INFO mapred.JobClient: Job Counters
13/08/07 08:07:01 INFO mapred.JobClient: Launched reduce tasks=1
13/08/07 08:07:01 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=6541
13/08/07 08:07:01 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
13/08/07 08:07:01 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
13/08/07 08:07:01 INFO mapred.JobClient: Rack-local map tasks=2
13/08/07 08:07:01 INFO mapred.JobClient: Launched map tasks=2
13/08/07 08:07:01 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=9293
13/08/07 08:07:01 INFO mapred.JobClient: File Input Format Counters
13/08/07 08:07:01 INFO mapred.JobClient: Bytes Read=50000000
13/08/07 08:07:01 INFO mapred.JobClient: File Output Format Counters
13/08/07 08:07:01 INFO mapred.JobClient: Bytes Written=50000000
13/08/07 08:07:01 INFO mapred.JobClient: FileSystemCounters
13/08/07 08:07:01 INFO mapred.JobClient: FILE_BYTES_READ=51000264
13/08/07 08:07:01 INFO mapred.JobClient: HDFS_BYTES_READ=50000218
13/08/07 08:07:01 INFO mapred.JobClient: FILE_BYTES_WRITTEN=102156988
13/08/07 08:07:01 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=50000000
13/08/07 08:07:01 INFO mapred.JobClient: Map-Reduce Framework
13/08/07 08:07:01 INFO mapred.JobClient: Map output materialized bytes=51000012
13/08/07 08:07:01 INFO mapred.JobClient: Map input records=500000
13/08/07 08:07:01 INFO mapred.JobClient: Reduce shuffle bytes=51000012
13/08/07 08:07:01 INFO mapred.JobClient: Spilled Records=1000000
13/08/07 08:07:01 INFO mapred.JobClient: Map output bytes=50000000
13/08/07 08:07:01 INFO mapred.JobClient: Total committed heap usage (bytes)=602996736
13/08/07 08:07:01 INFO mapred.JobClient: CPU time spent (ms)=6940
13/08/07 08:07:01 INFO mapred.JobClient: Map input bytes=50000000
13/08/07 08:07:01 INFO mapred.JobClient: SPLIT_RAW_BYTES=218
13/08/07 08:07:01 INFO mapred.JobClient: Combine input records=0
13/08/07 08:07:01 INFO mapred.JobClient: Reduce input records=500000
13/08/07 08:07:01 INFO mapred.JobClient: Reduce input groups=500000
13/08/07 08:07:01 INFO mapred.JobClient: Combine output records=0
13/08/07 08:07:01 INFO mapred.JobClient: Physical memory (bytes) snapshot=612827136
13/08/07 08:07:01 INFO mapred.JobClient: Reduce output records=500000
13/08/07 08:07:01 INFO mapred.JobClient: Virtual memory (bytes) snapshot=2305966080
13/08/07 08:07:01 INFO mapred.JobClient: Map output records=500000
13/08/07 08:07:01 INFO terasort.TeraSort: done
Counters: 30
Job Counters
Launched reduce tasks=1
SLOTS_MILLIS_MAPS=6541
Total time spent by all reduces waiting after reserving slots (ms)=0
Total time spent by all maps waiting after reserving slots (ms)=0
Rack-local map tasks=2
Launched map tasks=2
SLOTS_MILLIS_REDUCES=9293
File Input Format Counters
Bytes Read=50000000
File Output Format Counters
Bytes Written=50000000
FileSystemCounters
FILE_BYTES_READ=51000264
HDFS_BYTES_READ=50000218
FILE_BYTES_WRITTEN=102156988
HDFS_BYTES_WRITTEN=50000000
Map-Reduce Framework
Map output materialized bytes=51000012
Map input records=500000
Reduce shuffle bytes=51000012
Spilled Records=1000000
Map output bytes=50000000
Total committed heap usage (bytes)=602996736
CPU time spent (ms)=6940
Map input bytes=50000000
SPLIT_RAW_BYTES=218
Combine input records=0
Reduce input records=500000
Reduce input groups=500000
Combine output records=0
Physical memory (bytes) snapshot=612827136
Reduce output records=500000
Virtual memory (bytes) snapshot=2305966080
Map output records=500000
---- nn bench ----
hadoop jar hadoop-test-1.1.2.jar nnbench -operation create_write -maps 2 -reduces 1 -blockSize 1 -bytesToWrite 20 -bytesPerChecksum 1 -numberOfFiles 100 -replicationFactorPerFile 1
13/08/07 08:11:17 INFO hdfs.NNBench: -------------- NNBench -------------- :
13/08/07 08:11:17 INFO hdfs.NNBench: Version: NameNode Benchmark 0.4
13/08/07 08:11:17 INFO hdfs.NNBench: Date & time: 2013-08-07 08:11:17,388
13/08/07 08:11:17 INFO hdfs.NNBench:
13/08/07 08:11:17 INFO hdfs.NNBench: Test Operation: create_write
13/08/07 08:11:17 INFO hdfs.NNBench: Start time: 2013-08-07 08:11:01,121
13/08/07 08:11:17 INFO hdfs.NNBench: Maps to run: 2
13/08/07 08:11:17 INFO hdfs.NNBench: Reduces to run: 1
13/08/07 08:11:17 INFO hdfs.NNBench: Block Size (bytes): 1
13/08/07 08:11:17 INFO hdfs.NNBench: Bytes to write: 20
13/08/07 08:11:17 INFO hdfs.NNBench: Bytes per checksum: 1
13/08/07 08:11:17 INFO hdfs.NNBench: Number of files: 100
13/08/07 08:11:17 INFO hdfs.NNBench: Replication factor: 1
13/08/07 08:11:17 INFO hdfs.NNBench: Successful file operations: 200
13/08/07 08:11:17 INFO hdfs.NNBench:
13/08/07 08:11:17 INFO hdfs.NNBench: # maps that missed the barrier: 0
13/08/07 08:11:17 INFO hdfs.NNBench: # exceptions: 0
13/08/07 08:11:17 INFO hdfs.NNBench:
13/08/07 08:11:17 INFO hdfs.NNBench: TPS: Create/Write/Close: 65
13/08/07 08:11:17 INFO hdfs.NNBench: Avg exec time (ms): Create/Write/Close: 58.86
13/08/07 08:11:17 INFO hdfs.NNBench: Avg Lat (ms): Create/Write: 3.18
13/08/07 08:11:17 INFO hdfs.NNBench: Avg Lat (ms): Close: 55.59
13/08/07 08:11:17 INFO hdfs.NNBench:
13/08/07 08:11:17 INFO hdfs.NNBench: RAW DATA: AL Total #1: 636
13/08/07 08:11:17 INFO hdfs.NNBench: RAW DATA: AL Total #2: 11118
13/08/07 08:11:17 INFO hdfs.NNBench: RAW DATA: TPS Total (ms): 11772
13/08/07 08:11:17 INFO hdfs.NNBench: RAW DATA: Longest Map Time (ms): 6122.0
13/08/07 08:11:17 INFO hdfs.NNBench: RAW DATA: Late maps: 0
13/08/07 08:11:17 INFO hdfs.NNBench: RAW DATA: # of exceptions: 0
13/08/07 08:11:17 INFO hdfs.NNBench:
============ REGULAR HADOOP + DISK ============
---- terasort ----
hadoop jar hadoop-examples-1.1.2.jar teragen 500000 /user/hduser/terasort-input
hadoop jar hadoop-examples-1.1.2.jar terasort /user/hduser/terasort-input /user/hduser/terasort-output
13/08/07 08:26:03 INFO mapred.JobClient: Running job: job_201308070825_0002
13/08/07 08:26:04 INFO mapred.JobClient: map 0% reduce 0%
13/08/07 08:26:08 INFO mapred.JobClient: map 100% reduce 0%
13/08/07 08:26:15 INFO mapred.JobClient: map 100% reduce 33%
13/08/07 08:26:17 INFO mapred.JobClient: map 100% reduce 100%
13/08/07 08:26:17 INFO mapred.JobClient: Job complete: job_201308070825_0002
13/08/07 08:26:17 INFO mapred.JobClient: Counters: 30
13/08/07 08:26:17 INFO mapred.JobClient: Job Counters
13/08/07 08:26:17 INFO mapred.JobClient: Launched reduce tasks=1
13/08/07 08:26:17 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=6249
13/08/07 08:26:17 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
13/08/07 08:26:17 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
13/08/07 08:26:17 INFO mapred.JobClient: Launched map tasks=2
13/08/07 08:26:17 INFO mapred.JobClient: Data-local map tasks=2
13/08/07 08:26:17 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=9218
13/08/07 08:26:17 INFO mapred.JobClient: File Input Format Counters
13/08/07 08:26:17 INFO mapred.JobClient: Bytes Read=50000000
13/08/07 08:26:17 INFO mapred.JobClient: File Output Format Counters
13/08/07 08:26:17 INFO mapred.JobClient: Bytes Written=50000000
13/08/07 08:26:17 INFO mapred.JobClient: FileSystemCounters
13/08/07 08:26:17 INFO mapred.JobClient: FILE_BYTES_READ=51000264
13/08/07 08:26:17 INFO mapred.JobClient: HDFS_BYTES_READ=50000218
13/08/07 08:26:17 INFO mapred.JobClient: FILE_BYTES_WRITTEN=102156990
13/08/07 08:26:17 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=50000000
13/08/07 08:26:17 INFO mapred.JobClient: Map-Reduce Framework
13/08/07 08:26:17 INFO mapred.JobClient: Map output materialized bytes=51000012
13/08/07 08:26:17 INFO mapred.JobClient: Map input records=500000
13/08/07 08:26:17 INFO mapred.JobClient: Reduce shuffle bytes=51000012
13/08/07 08:26:17 INFO mapred.JobClient: Spilled Records=1000000
13/08/07 08:26:17 INFO mapred.JobClient: Map output bytes=50000000
13/08/07 08:26:17 INFO mapred.JobClient: Total committed heap usage (bytes)=602996736
13/08/07 08:26:17 INFO mapred.JobClient: CPU time spent (ms)=6690
13/08/07 08:26:17 INFO mapred.JobClient: Map input bytes=50000000
13/08/07 08:26:17 INFO mapred.JobClient: SPLIT_RAW_BYTES=218
13/08/07 08:26:17 INFO mapred.JobClient: Combine input records=0
13/08/07 08:26:17 INFO mapred.JobClient: Reduce input records=500000
13/08/07 08:26:17 INFO mapred.JobClient: Reduce input groups=500000
13/08/07 08:26:17 INFO mapred.JobClient: Combine output records=0
13/08/07 08:26:17 INFO mapred.JobClient: Physical memory (bytes) snapshot=609116160
13/08/07 08:26:17 INFO mapred.JobClient: Reduce output records=500000
13/08/07 08:26:17 INFO mapred.JobClient: Virtual memory (bytes) snapshot=2309636096
13/08/07 08:26:17 INFO mapred.JobClient: Map output records=500000
13/08/07 08:26:17 INFO terasort.TeraSort: done
Counters: 30
Job Counters
Launched reduce tasks=1
SLOTS_MILLIS_MAPS=6249
Total time spent by all reduces waiting after reserving slots (ms)=0
Total time spent by all maps waiting after reserving slots (ms)=0
Launched map tasks=2
Data-local map tasks=2
SLOTS_MILLIS_REDUCES=9218
File Input Format Counters
Bytes Read=50000000
File Output Format Counters
Bytes Written=50000000
FileSystemCounters
FILE_BYTES_READ=51000264
HDFS_BYTES_READ=50000218
FILE_BYTES_WRITTEN=102156990
HDFS_BYTES_WRITTEN=50000000
Map-Reduce Framework
Map output materialized bytes=51000012
Map input records=500000
Reduce shuffle bytes=51000012
Spilled Records=1000000
Map output bytes=50000000
Total committed heap usage (bytes)=602996736
CPU time spent (ms)=6690
Map input bytes=50000000
SPLIT_RAW_BYTES=218
Combine input records=0
Reduce input records=500000
Reduce input groups=500000
Combine output records=0
Physical memory (bytes) snapshot=609116160
Reduce output records=500000
Virtual memory (bytes) snapshot=2309636096
Map output records=500000
---- nn bench ----
hadoop jar hadoop-test-1.1.2.jar nnbench -operation create_write -maps 2 -reduces 1 -blockSize 1 -bytesToWrite 20 -bytesPerChecksum 1 -numberOfFiles 100 -replicationFactorPerFile 1
13/08/07 08:30:45 INFO hdfs.NNBench: -------------- NNBench -------------- :
13/08/07 08:30:45 INFO hdfs.NNBench: Version: NameNode Benchmark 0.4
13/08/07 08:30:45 INFO hdfs.NNBench: Date & time: 2013-08-07 08:30:45,180
13/08/07 08:30:45 INFO hdfs.NNBench:
13/08/07 08:30:45 INFO hdfs.NNBench: Test Operation: create_write
13/08/07 08:30:45 INFO hdfs.NNBench: Start time: 2013-08-07 08:30:30,955
13/08/07 08:30:45 INFO hdfs.NNBench: Maps to run: 2
13/08/07 08:30:45 INFO hdfs.NNBench: Reduces to run: 1
13/08/07 08:30:45 INFO hdfs.NNBench: Block Size (bytes): 1
13/08/07 08:30:45 INFO hdfs.NNBench: Bytes to write: 20
13/08/07 08:30:45 INFO hdfs.NNBench: Bytes per checksum: 1
13/08/07 08:30:45 INFO hdfs.NNBench: Number of files: 100
13/08/07 08:30:45 INFO hdfs.NNBench: Replication factor: 1
13/08/07 08:30:45 INFO hdfs.NNBench: Successful file operations: 200
13/08/07 08:30:45 INFO hdfs.NNBench:
13/08/07 08:30:45 INFO hdfs.NNBench: # maps that missed the barrier: 0
13/08/07 08:30:45 INFO hdfs.NNBench: # exceptions: 0
13/08/07 08:30:45 INFO hdfs.NNBench:
13/08/07 08:30:45 INFO hdfs.NNBench: TPS: Create/Write/Close: 87
13/08/07 08:30:45 INFO hdfs.NNBench: Avg exec time (ms): Create/Write/Close: 42.895
13/08/07 08:30:45 INFO hdfs.NNBench: Avg Lat (ms): Create/Write: 3.16
13/08/07 08:30:45 INFO hdfs.NNBench: Avg Lat (ms): Close: 39.655
13/08/07 08:30:45 INFO hdfs.NNBench:
13/08/07 08:30:45 INFO hdfs.NNBench: RAW DATA: AL Total #1: 632
13/08/07 08:30:45 INFO hdfs.NNBench: RAW DATA: AL Total #2: 7931
13/08/07 08:30:45 INFO hdfs.NNBench: RAW DATA: TPS Total (ms): 8579
13/08/07 08:30:45 INFO hdfs.NNBench: RAW DATA: Longest Map Time (ms): 4547.0
13/08/07 08:30:45 INFO hdfs.NNBench: RAW DATA: Late maps: 0
13/08/07 08:30:45 INFO hdfs.NNBench: RAW DATA: # of exceptions: 0
13/08/07 08:30:45 INFO hdfs.NNBench:
============ REGULAR HADOOP + KOVE ============
---- terasort ----
hadoop jar hadoop-examples-1.1.2.jar teragen 500000 /user/hduser/terasort-input
hadoop jar hadoop-examples-1.1.2.jar terasort /user/hduser/terasort-input /user/hduser/terasort-output
13/08/07 08:35:25 INFO mapred.JobClient: Running job: job_201308070834_0002
13/08/07 08:35:26 INFO mapred.JobClient: map 0% reduce 0%
13/08/07 08:35:31 INFO mapred.JobClient: map 100% reduce 0%
13/08/07 08:35:38 INFO mapred.JobClient: map 100% reduce 33%
13/08/07 08:35:40 INFO mapred.JobClient: map 100% reduce 100%
13/08/07 08:35:40 INFO mapred.JobClient: Job complete: job_201308070834_0002
13/08/07 08:35:40 INFO mapred.JobClient: Counters: 30
13/08/07 08:35:40 INFO mapred.JobClient: Job Counters
13/08/07 08:35:40 INFO mapred.JobClient: Launched reduce tasks=1
13/08/07 08:35:40 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=6390
13/08/07 08:35:40 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
13/08/07 08:35:40 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
13/08/07 08:35:40 INFO mapred.JobClient: Rack-local map tasks=2
13/08/07 08:35:40 INFO mapred.JobClient: Launched map tasks=2
13/08/07 08:35:40 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=9240
13/08/07 08:35:40 INFO mapred.JobClient: File Input Format Counters
13/08/07 08:35:40 INFO mapred.JobClient: Bytes Read=50000000
13/08/07 08:35:40 INFO mapred.JobClient: File Output Format Counters
13/08/07 08:35:40 INFO mapred.JobClient: Bytes Written=50000000
13/08/07 08:35:40 INFO mapred.JobClient: FileSystemCounters
13/08/07 08:35:40 INFO mapred.JobClient: FILE_BYTES_READ=51000264
13/08/07 08:35:40 INFO mapred.JobClient: HDFS_BYTES_READ=50000218
13/08/07 08:35:40 INFO mapred.JobClient: FILE_BYTES_WRITTEN=102162937
13/08/07 08:35:40 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=50000000
13/08/07 08:35:40 INFO mapred.JobClient: Map-Reduce Framework
13/08/07 08:35:40 INFO mapred.JobClient: Map output materialized bytes=51000012
13/08/07 08:35:40 INFO mapred.JobClient: Map input records=500000
13/08/07 08:35:40 INFO mapred.JobClient: Reduce shuffle bytes=51000012
13/08/07 08:35:40 INFO mapred.JobClient: Spilled Records=1000000
13/08/07 08:35:40 INFO mapred.JobClient: Map output bytes=50000000
13/08/07 08:35:40 INFO mapred.JobClient: Total committed heap usage (bytes)=602996736
13/08/07 08:35:40 INFO mapred.JobClient: CPU time spent (ms)=6660
13/08/07 08:35:40 INFO mapred.JobClient: Map input bytes=50000000
13/08/07 08:35:40 INFO mapred.JobClient: SPLIT_RAW_BYTES=218
13/08/07 08:35:40 INFO mapred.JobClient: Combine input records=0
13/08/07 08:35:40 INFO mapred.JobClient: Reduce input records=500000
13/08/07 08:35:40 INFO mapred.JobClient: Reduce input groups=500000
13/08/07 08:35:40 INFO mapred.JobClient: Combine output records=0
13/08/07 08:35:40 INFO mapred.JobClient: Physical memory (bytes) snapshot=611500032
13/08/07 08:35:40 INFO mapred.JobClient: Reduce output records=500000
13/08/07 08:35:40 INFO mapred.JobClient: Virtual memory (bytes) snapshot=2300420096
13/08/07 08:35:40 INFO mapred.JobClient: Map output records=500000
13/08/07 08:35:40 INFO terasort.TeraSort: done
Counters: 30
Job Counters
Launched reduce tasks=1
SLOTS_MILLIS_MAPS=6390
Total time spent by all reduces waiting after reserving slots (ms)=0
Total time spent by all maps waiting after reserving slots (ms)=0
Rack-local map tasks=2
Launched map tasks=2
SLOTS_MILLIS_REDUCES=9240
File Input Format Counters
Bytes Read=50000000
File Output Format Counters
Bytes Written=50000000
FileSystemCounters
FILE_BYTES_READ=51000264
HDFS_BYTES_READ=50000218
FILE_BYTES_WRITTEN=102162937
HDFS_BYTES_WRITTEN=50000000
Map-Reduce Framework
Map output materialized bytes=51000012
Map input records=500000
Reduce shuffle bytes=51000012
Spilled Records=1000000
Map output bytes=50000000
Total committed heap usage (bytes)=602996736
CPU time spent (ms)=6660
Map input bytes=50000000
SPLIT_RAW_BYTES=218
Combine input records=0
Reduce input records=500000
Reduce input groups=500000
Combine output records=0
Physical memory (bytes) snapshot=611500032
Reduce output records=500000
Virtual memory (bytes) snapshot=2300420096
Map output records=500000
---- nn bench ----
hadoop jar hadoop-test-1.1.2.jar nnbench -operation create_write -maps 2 -reduces 1 -blockSize 1 -bytesToWrite 20 -bytesPerChecksum 1 -numberOfFiles 100 -replicationFactorPerFile 1
13/08/07 08:42:43 INFO hdfs.NNBench: -------------- NNBench -------------- :
13/08/07 08:42:43 INFO hdfs.NNBench: Version: NameNode Benchmark 0.4
13/08/07 08:42:43 INFO hdfs.NNBench: Date & time: 2013-08-07 08:42:43,678
13/08/07 08:42:43 INFO hdfs.NNBench:
13/08/07 08:42:43 INFO hdfs.NNBench: Test Operation: create_write
13/08/07 08:42:43 INFO hdfs.NNBench: Start time: 2013-08-07 08:42:29,426
13/08/07 08:42:43 INFO hdfs.NNBench: Maps to run: 2
13/08/07 08:42:43 INFO hdfs.NNBench: Reduces to run: 1
13/08/07 08:42:43 INFO hdfs.NNBench: Block Size (bytes): 1
13/08/07 08:42:43 INFO hdfs.NNBench: Bytes to write: 20
13/08/07 08:42:43 INFO hdfs.NNBench: Bytes per checksum: 1
13/08/07 08:42:43 INFO hdfs.NNBench: Number of files: 100
13/08/07 08:42:43 INFO hdfs.NNBench: Replication factor: 1
13/08/07 08:42:43 INFO hdfs.NNBench: Successful file operations: 200
13/08/07 08:42:43 INFO hdfs.NNBench:
13/08/07 08:42:43 INFO hdfs.NNBench: # maps that missed the barrier: 0
13/08/07 08:42:43 INFO hdfs.NNBench: # exceptions: 0
13/08/07 08:42:43 INFO hdfs.NNBench:
13/08/07 08:42:43 INFO hdfs.NNBench: TPS: Create/Write/Close: 90
13/08/07 08:42:43 INFO hdfs.NNBench: Avg exec time (ms): Create/Write/Close: 42.665
13/08/07 08:42:43 INFO hdfs.NNBench: Avg Lat (ms): Create/Write: 3.015
13/08/07 08:42:43 INFO hdfs.NNBench: Avg Lat (ms): Close: 39.61
13/08/07 08:42:43 INFO hdfs.NNBench:
13/08/07 08:42:43 INFO hdfs.NNBench: RAW DATA: AL Total #1: 603
13/08/07 08:42:43 INFO hdfs.NNBench: RAW DATA: AL Total #2: 7922
13/08/07 08:42:43 INFO hdfs.NNBench: RAW DATA: TPS Total (ms): 8533
13/08/07 08:42:43 INFO hdfs.NNBench: RAW DATA: Longest Map Time (ms): 4437.0
13/08/07 08:42:43 INFO hdfs.NNBench: RAW DATA: Late maps: 0
13/08/07 08:42:43 INFO hdfs.NNBench: RAW DATA: # of exceptions: 0
13/08/07 08:42:43 INFO hdfs.NNBench:
Conclusion
It has been shown that running Hadoop NameNode on a Kove XPD improves cluster reliability and removes the memory size limitation usual for the RAM-based NameNode.
Planned enhancements include making fuller utilitzation of all the capabilities of the Kove XPD, described here http://kove.com/, such as its fast block copy of terabytes of data in a matter of seconds.